

برای لیست شدن در موتورهای جستجو، مهمترین محتوای شما باید به فرمت متن HTML باشد. تصاویر، فایل های فلش، اپلت های جاوا و سایر محتواهای غیرمتنی، اغلب توسط موتورهای جستجو، صرفنظر می شوند. راحت ترین راه برای حصول اطمینان در مورد این که کلمات و عباراتی که به بازدیدکنندگان نمایش می دهید، در موتورهای جستجو نیز قابل مشاهده هستند، قرار دادن آن به شکل متن HTML در صفحه است. اما، روش های پیشرفته تری برای کسانی که فرمت بیشتر یا شیوه های نمایش بصری می خواهند، وجود دارد:

" من فکر می کنم مشکلی در یافتن منت است. این سایت بزرگ فلش را برای شعبده بازی پانداها ایجاد کردم ولی هیچ جایی در گوگل نشان داده نشدم، جریان چیست؟"
وب سایت های بسیاری، مشکلات چشمگیری جهت ایندکس شدن دارند. بنابراین بررسی مجدد، با ارزش است. با استفاده از ابزارهایی نظیر cash گوگل، SEO-browser.com یا Mozbar، می توانید مشاهده کنید چه عناصری از محتوای شما قابل مشاهده هستند و در موتورهای جستجو ایندکس می شوند. نگاهی به Google's text cache of this page you are reading now داشته باشید. نگاه کنید که چقدر متفاوت به نظر می رسد؟
ساختارهای اتصال ضعیف، منجر به نرسیدن موتورهای جستجو به همه ی محتوای وب سایت می شود. در سایر موارد، ساختار لینک ضعیف، به موتورهای جستجو، امکان خزش محتوا را می دهد اما آن را به طور حداقل بی پناه می نهد و توسط موتورهای جستجو "غیرمهم" فرض می شود.
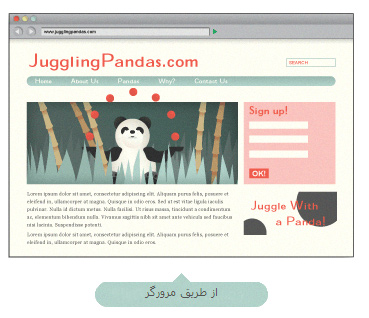
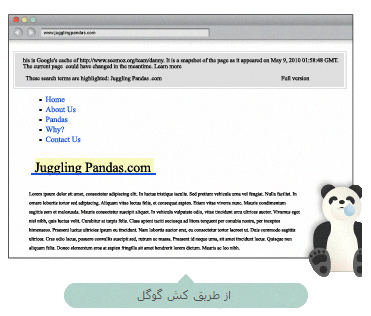
با استفاده از ویژگی های cash گوگل، قادر به مشاهده ی وب سایت از دید گوگل هستیم. صفحه ی اصلی Jugglingpandas.com حاوی همه ی اطلاعاتی که ما مشاهده می کنیم نیست. این امر آن را برای نفسیر ارتباط توسط موتورهای جستجو را دشوار می سازد.


همانطور که موتورهای جستجو نیاز دارند که محتوا را برای لیست صفحات در اندیس های مبتنی بر کلیدواژه ی بزرگ خود ببینند، همچنین نیاز به مشاهده ی لینک ها برای یافتن محتوا نیز دارند. یک ساختار لینک قابل خزش-که به عنکبوت ها امکان مرور مسیرهای یک وبسایت را می دهد-برای یافتن همه ی صفحات بر یک وبسایت، حیاتی است. صدها از هزاران سایت، اشتباهات بحرانی را در ساختاربندی راه های گردش خود، به شیوه ای که موتورهای جستجو نمی توانند، در سایت گردش کنند، می کنند، بنابراین بر قابلیت لیست شدن صفحات در اندیس های موتورهای جستجو تاثیر می گذارند.
در زیر، شرح می دهیم که چطور این مشکل رخ می دهد:

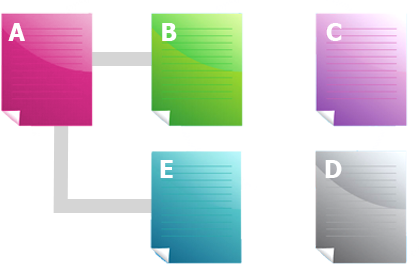
در مثال بالا، عنکبوت گوگل، به صفحه ی "A" رسیده است و لینک به صفحات "B" و "E" را مشاهده می کند. اما، گرچه C و D ممکن است صفحات مهمی بر سایت باشند، عنکبوت هیچ راهی برای رسیدن به آن ها (یا حتی آگاهی از حضور آن ها) ندارد. این امر بدین دلیل است که هیچ نقطه اتصال مستقیم و قابل خزشی، به این صفحات وجود ندارد. از نظر گوگل، این صفحات وجود ندارند-در صورتی که عنکبوت نتواند به این صفحات برسد، محتوای عالی، کلیدواژه های خوب و بازاریابی عالی، هیچ تغییری ایجاد نمی کند.

بیایید به برخی دلایل معمول در مورد دلیل قابل دسترس نبودن صفحات، نگاهی داشته باشیم.
از نظر فنی، لینک ها در هر دوی فریم ها و I-فریم ها، قابل خزش هستند و هر دو موارد ساختاری را برای موتورها بر اساس سازمان نمایش می دهند. اگر شما یک کاربر پیشرفته با فهم فنی خوبی در مورد چگونگی اندیس گذاری و دنبال کردن لینک ها در فریم ها نباشید، بهتر است که از آن ها دور بمانید.
اگر شما از جاوااسکریپت برای لینک ها استفاده می کنید، ممکن است در یابید که موتورهای جستجو یا لینک های توکار درون آن را خزش نمی کنند یا وزن کمی به آن ها می دهند. لینک های استاندارد HTML باید جاوااسکریپت را در هر صفحه ای که می خواهید خزش کنید، جایگزین کنند.
فایل Meta Robots tag and the Robots.txt، به صاحب یک سایت امکان محدود کردن دسترسی به یک سایت را می دهد. اخیرا هشدار داده شده است که بسیاری از وبمسترها غیرعمدی از این ویژگی به عنوان تلاشی برای بلاک کردن دسترسی افراد نامجاز استفاده کرده اند.
موتورهای جستجو، لینک های زیادی را بر یک صفحه ی داده شده، خزش می کنند-نه یک میزان نامتناهی. این امر محدودیت لازم برای کاهش هرزنامه و نگهداری رتبه بندی را از بین می برد. صفحات با صدها لینک بر آن ها، در خطر، عدم پویش لینک ها و اندیس آن ها هستند.
اگر نیاز دارید که کاربران یک فرم آنلاین را قبل از دسترسی به محتوای خاصی پر کنند، موتورهای جستجو ممکن است هرگز آن صفحات حفاظت شده را نبینند. فرم ها می توانند حاوی یک ورود محافظت شده توسط پسورد یا یک بررسی کامل باشند. در هر مورد، خزنده های وب به طور عمومی تلاشی به ارائه ی فرم ها نمی کنند و بنابراین هر محتوا یا لینکی که از طریق فرم ها ارائه می شوند، برای موتورهای جستجو، غیرقابل مشاهده هستند.
گرچه این امر مستقیما مرتبط با هشدار بالا در مورد فرم هاست، این یک مشکل معمول است که باید ذکر شود. برخی وبمسترها عقیده دارند که اگر یک کادر محاوره را در سایتشان قرار دهند، آنگاه موتورها قادر به یافتن هر چیزی که بازدید کننده جستجو می کند، می باشند. متاسفانه، خزندگان جستجو را برای یافتن محتوا، اجرا نمی کنند و بنابراین میلیون ها صفحه پشت دیوارهای غیرقابل دسترسی، مخفی می مانند و تا زمانی که یک صفحه ی خزش شده به آن ها لینک نشود، گمنام می مانند.
لینک های تعبیه شده در سایت پاندا (در مثال بالا) یک شرح خوب از این پدیده است. گرچه ده ها پاندا به یک صفحه ی پاندا لینک شده اند، هیچ خزنده ای نمی تواند به آن ها از طریق ساختار لینک سایت برسد و برای موتورهای جستجو غیرقابل مشاهده می شود ( و توسط جستجوهایی که یک درخواست را اجرا می کنند، غیرقابل بازیابی می شود).
اگر شما از این دام ها اجتناب کنید، لینک های تمیز و قابل پویش HTML خواهید داشت که امکان دسترسی راحت به محتوای صفحات شما را می دهد.
Rel="nofollow" را می توان با سینتکس زیر استفاده کرد:
Lousy Punks
لینک ها می توانند ویژگی های زیادی داشته باشند که در آن ها استفاده شوند، اما موتورها تقریبا همه ی آن ها را با افزودن ویژگی rel=nofollow به تگ لینک صرفنظر می کنند، با این کار به موتور جستجو گفته ایم که مالک سایت، نمی خواهد این لینک به شکل نرمال تفسیر شود، "حق رای ویرایشی".
Nofollow به موتورهای جستجو، دستور می دهد که یک لینک را دنبال نکنند (گرچه برخی ها دنبال می کنند). تگ nofollow، به عنوان روشی برای متوقف کردن نظر گذاری خودکار بلاگ ها، کتاب های مهمان و لینک تزریق هرزنامه می باشد اما در طول زمان به روشی برای عدم پویش هر لینکی که به شکل عادی عبور می شود، تبدیل شده است. لینک های تگ شده توسط nofollow، به میزان کمی متفاوت توسط هر یک از موتورها، تفسیر می شوند اما به وضوح، وزنی معادل لینک هایی که "followed" هستند، ندارند.
این لینک ها بخشی طبیعی از نمایه لینک پراکنده هستند. یک وبسایت با تعداد زیادی لینک ها درونی، بسیاری از لینک های nofollow را در خود دارد و این چیز بدی نیست. در واقع فاکتورهای رتبه دهی SEOmoz، نشان دادند که سایت های با رتبه ی بالا، درصد بالاتری از لینک های nofollowed را نسبت به سایت های رتبه دهی پایین تر دارند.
کلیدواژه ها برای فرآیند جستجو، اساسی هستند-آن ها اجزای سازنده ی زبان و جستجو هستند. در واقع، کل علوم بازیابی اطلاعات (شامل موتورهای جستجوی مبتنی بر وب، نظیر گوگل) بر اساس کلیدواژه ها هستند. چون موتور محتوای صفحات را در سراسر وب، خزش و اندیس گذاری می کند، رد این صفحات را در اندیس های مبتنی بر کلیدواژه نگه می دارد. بنابراین، به جای نگهداری 25 بیلیون صفحه ی وب در یک پایگاه داده، موتورها، میلیون ها و میلیون ها، پایگاه داده ی کوچکتر دارند که هر یک بر یک عبارت یا اصطلاح کلیدواژه ی خاص تمرکز دارند. این امر بازیابی داده ی مورد نیاز را در بخشی از ثانیه برای موتورهای جستجو، خیلی سریعتر می سازد.
به وضوح، اگر شما می خواهید که شانس رتبه دهی در نتایج جستجو برای "سگ" داشته باشید، عاقلانه است که اطمینان حاصل کنید که "سک" بخشی از محتوای قابل اندیس گذاری محتوای مستند شما باشد.
لینک های nofollow را دنبال نمی کند و هیچ یک از این لینک ها رتبه دهی صفحه را انتقال نمی دهند. ضرورتا استفاده از nofollow منجر می شود که لینک ها را از گراف پویشی خود حذف کنیم. لینک های nofollow، هیچ وزنی نداشته و به عنوان متن HTML تفسیر نمی شوند ( مثل این که این لینک ها وجود ندارند). بدین معنی که بسیاری از وبمسترهاعقیده دارند که گرچه یک لینک nofollow یک سایت با اختیار بالا را شکل می دهد، نظیر ویکی پدیا، می تواند به عنوان نشانگر اعتماد، تفسیر شود.
Bing که نتایج جستجوی یاهو را ارائه می کند، همچنین بیان کرده است که شامل لینک های nofollowed در گراف لینک نمی شود. در گذشته، همچنین بیان کرده اند که لینک های nofollow هنوز توسط خزندگانشان به عنوان روشی برای تشخیص صفحات جدید، استفاده می شود. بنابراین چون آن ها ممکن است که این لینک ها را دنبال کنند، به عنوان روشی برای تاثیر گذاری بر رتبه دهی، بر نمی شمرند.

کلیدواژه ها بر هدف جستجوی ما و تعامل با موتورهای جستجو، تعامل دارند. برای مثال، یک الگوی جستجوی معمول، چیزی شبیه به این خواهد بود:
وقتی که یک جستجو انجام می شود، موتور صفحاتی را بر اساس تطابق با کلمه های وارد شده در کادر جستجو، می یابد. سایر داده ها، نظیر ترتیب کلمات ("tanks shooting" در مقابل "shooting tanks")، املاء، علامت گذاری و بزرگ و کوچک بودن حروف، اطلاعات اضافی را فراهم می کنند که موتورهای جستجو برای بازیابی صفحه ی درست و رتبه دهی آنها استفاده می کند.
برای کمک به انجام این، موتورهای جستجو، راه هایی را که کلیدواژه ها بر صفحات استفاده شده اند برای تعیین ارتباط یک مستند خاص به یک درخواست، اندازه گیری می کند. یکی از بهترین روش ها برای بهینه سازی رتبه بندی یک صفحه، حصول اطمینان از این است که کلیدواژه ها به طور غالب، در عناوین، متن و متاداده استفاده شده اند.
به طور عمومی، هر چه کلیدواژه های شما خاص تر باشند، شانس رتبه بندی شما بر اساس رقابت کمتر، بهتر خواهد بود. نقشه گرافیکی سمت چپ، ارتباط عبارت جهانی کتاب را به عنوان خاص "داستان دو شهر" نشان می دهد. توجه داشته باشید که در حالی که نتایج زیادی وجود دارد (اندازه کشور) تعداد زیادی نتایج کمتر وجود دارد و بنابراین برای نتیجه ی خاص و دقیق رقابت وجود دارد.
با به وجود آمدن جستجوی آنلاین، افراد از کلیدواژه های بد برای تعامل با موتور جستجو استفاده کرده اند. این امر شامل، انباشتن کلیدواژه ها در متن، url، تگهای متا و لینک هاست. متاسفانه، این تاکتیک، تقریبا همیشه، ضرر بیشتری به وبسایت شما می زند.
در روزهای اولیه، موتورهای جستجو بر استفاده از کلیدواژه به عنوان علامت ارتباط اولیه، بدون توجه به چگونگی استفاده ی واقعی کلیدواژه ها، تکیه داشتند. امروزه، گرچه موتورهای جستجو هنوز نمی توانند به خوبی انسان متن را بخوانند، اما استفاده از یادگیری ماشین به آن ها این امکان را می دهد که به این ایده آل نزدیکتر شوند.
بهترین تمرین، استفاده ی طبیعی و استراتژیک از کلیدواژه های خود است. اگر صفحه ی شما کلید واژه ی "برج ایفل" را در بر دارد، آنگاه به طور طبیعی محتوایی در مورد خود برج ایفل را وارد کنید. به عبارت دیگر، اگر به سادگی کلمات "برج ایفل" را بر یک صفحه با محتوای غیرمرتبط قرار دهید، نظیر صفحه ای در مورد نژاد سگ، آنگاه تلاش ما برای رتبه دهی "برج ایفل" بی فایده و بی ثمر خواهد بود.
چگالی کلیدواژه، همانطور که توسط دکتر Edel Garcia شرح داده می شود، بخشی از الگوریتم های رتبه دهی مدرن نیست.
اگر دو مستند، D1 و D2، از 1000 عبارت (l=1000) تشکیل شده باشند و یک عبارت را 20 بار تکرار کنند (tf=20)، آنگاه یک تحلیل کننده ی چگالی کلیدواژه، به شما می گوید که برای چگالی کلیدواژه مستند KD=tf/l=0.020 و یا %2* (KD) برای آن عبارت است. مقادیر معادل، وقتی که tf=10 و l=500 باشد، حاصل می شوند. به وضوح، تحلیلگر چگالی کلیدواژه، مشخص نمی کند که کدام مستند، مرتبط تر است. تحلیل چگالی یا نرخ چگالی کلیدواژه، هیچ چیزی به ما در مورد آن نمی گوید:
گفته شده است که استفاده از کلیدواژه، هنوز بخشی از الگوریتم های رتبه دهی موتورهای جستجو هستند و می توانیم از برخی بهترین تمارین برای استفاده از کلیدواژه برای کمک به ایجاد صفحاتی که به حالت بهینه نزدیک هستند، استفاده کنیم. در اینجا، در SEOmoz، در تست های زیادی در گیر هستیم و تعداد زیادی از نتایج جستجو را مشاهده کرده و بر اساس تاکتیک های استفاده از کلیدواژه انتقال یافته ایم. وقتی با یک از سایت های خودمان کار می کنیم، این فرآیندی است که پیشنها د می کنیم:
چگالی کلیدواژه از محتوا، کیفیت، معانی و ارتباط مجزا شده است.
آنگاه چگالی صفحه ی بهینه به چه شکل به نظر می آید؟ یک صفحه بهینه برای عبارت "کفش های ورزشی" چیزی شبیه به شکل زیر است:

عنصر عنوان یک صفحه، به معنی یک شرح دقیق و درست از محتوای صفحه است که برای تجربه کاربر و بهینه سازی موتور جستجو، حیاتی است.
چون تگ های عنوان، بخش مهمی از بهینه سازی موتور جستجو هستند، بهترین تمارین زیر برای ایجاد تگ عنوان، نکات خوبی را ارائه می کنند. توصیه های زیر، بخش های حیاتی از تگ های عنوان بهینه را برای موتورهای جستجو و اهداف استفاده پوشش می دهند.
موتورهای جستجو فقط 65-75 کاراکتر اول از یک تگ عنوان را در نتایج جستجو نشان می دهند. (بعد از این طول، یک حذف "..." را برای نشان دادن زمانی که تگ عنوان قطع شده است، نمایش می دهند) همچنین محدودیت کلی است که توسط بیشتر سایت های رسانه ی اجتماعی، ممکن شده است بنابراین توجه به این محدودیت عموما عاقلانه است. اما اگر چندین کلیدواژه را مد نظر دارید، (یا یک عبارت طولانی خاص را مد نظر دارید) و داشتن آن ها در تگ عنوان برای رتبه بندی ضروری است، پیشنهاد می کنیم که به خواندن ادامه دهید.
کلیدواژه های مهم را نزدیک به ابتدا قرار دهید
هر چه کلیدواژه های شما به شروع تگ عنوان نزدیکتر باشد، برای رتبه بندی مفیدتر خواهد بود و احتمال بیشتری دارد که یک کاربر بر آنها در نتایج جستجو کلیک کند.
در SEOmoz، علاقمندیم که هر تگ عنوان را با ذکر یک نام تجاری خاتمه دهیم، چون این امر به افزایش توجه به مارک تجاری کمی می کند و یک نرخ کلیک بالاتری را برای افرادی که با نام تجاری آشنا هستند، فراهم می کند. برخی اوقات، قرار دادن نام تجاری در شروع تگ عنوان، منطقی است، نظیر صفحه ی خانگی شما. چون کلمات در شروع تگ عنوان، وزن بیشتری دارند، در مورد این که سعی در رتبه دهی چه چیزی دارید اندیشه کنید.
به تاثیر قابلیت خواندن و احساسی توجه کنید.
تگ های عنوان، باید قابل خواندن و شرح دادن باشند. ایجاد یک تگ عنوان اجباری، بازدیدهای بیشتری را از نتایج جستجو ایجاد می کند و می تواند بازدیدکنندگان را به سایت شما بیاورد. بنابراین، نه تنها فکر کردن در مورد بهینه سازی و استفاده از کلیدواژه، مهم است بلکه تجربه کلی کاربر نیز مهم است. تگ عنوان، اولین تعامل بازدید کننده از نام تجاری شماست و باید حداکثر تاثیر ممکن را انتقال دهد.
تگ عنوان از هر صفحه، در بالای نرم افزار مرورگر اینترنت است و اغلب به عنوان وقتی که محتوای شما از طریق رسانه اجتماعی منتشر می شود، استفاده می شود.
دلیل نهایی مهم برای ایجاد تگ های عنوان شرح دهنده و مملو از کلیدواژه، برای رتبه دهی در موتورهای جستجو است. در SEOmoz، 94 درصد از تگ های عنوان در مهمترین مکان برای استفاده از کلیدواژه ها برای حصول رتبه بندی بالاتر قرار دارند.
قصد تگ های متا اساسا فراهم کردن یک پروکسی برای اطلاعات در مورد محتوای وبسایت است. چندین تگ متا، در زیر به همراه شرحی از استفاده ی آن ها، لیست شده است.
تگ ربات های متا، می تواند به عنوان یک فعالیت برای کنترل خزش موتور جستجو در سطح صفحه استفاده شود (برای همه ی موتورهای بزرگ). چندین راه برای استفاده از ربات های متا برای کنترل چگونگی رفتار موتورهای جستجو با یک صفحه، وجود دارد:
رهنمود سرآیند HTTIP از تگ X-Robots، اهدف مشابهی را ایجاد می کند. این تکنیک به خصوص به خوبی برای مفاهیم در فایل های غیر HTML، نظیر تصاویر به خوبی کار می کند.
تگ شرح متا، به عنوان شرحی خلاصه از محتوای صفحه ارائه می کند. موتورهای جستجو، از کلیدواژه ها یا عبارات در تگ برای رتبه دهی استفاده نمی کنند اما شرح متا، منبع اولیه برای متن نشان داده شده ی جزئی در زیر لیست نتایج است.
تگ شرح متا، از توابع کپی تبلیغاتی، استفاده کرده و خوانندگان را به سایت شما از نتایج می آورد و بنابراین بخش خیلی مهمی از بازاریابی جستجو است.
شرح متا، می تواند خیلی طولانی باشد، اما موتورهای جستجو، عموما، قسمت های طولانی تر از 160 کاراکتر را حذف می کنند، بنابراین عاقلانه است که در همین محدوده قرار بگیرید.
در غیاب شرح متا، موتورهای جستجو از سایر عناصر صفحه، جستجوی جزئی را فراهم می کنند. برای صفحاتی که چندین کلیدواژه و عنوان را در بر دارند، این یک تاکتیک کاملا معتبر است.
نه به مهمی تگ های متا
کلیدواژه های متا، زمانی ارزش داشتند اما دیگر برای بهینه سازی موتورهای جستجو مهم نیستند. برای کسب اطلاعات بیشتر در مورد تاریخچه و دلیل این که چرا کلیدواژه های متا از بحث حذف شده اند، تگ کلیدواژه های متا 101 را از searchengineland مطالعه نمایید.
تگ های Meta refresh, meta revisit-after, meta content type و غیره
گرچه این تگ ها، برای بهینه سازی موتور جستجو استفاده شده اند، برای فرآیند کمتر بحرانی هستند و بنابراین پاسخگویی به آن با جزئیات بیشتر را به تگ های متای در قسمت کمک ابزارهای وبمستر گوگل، واگذار کرده ایم.
URL، آدرس های وب برای آدرس دهی مستند خاص، از ارزش زیادی از نقطه نظر جستجو برخوردار هستند. آنها در چندین مکان مهم، پدیدار می شوند.

چون موتورهای جستجو، URL ها را در نتایج نشان می دهند، می توانند بر کلیک و قابلیت مشاهده تاثیر بگذارند. همچنین URL ها در رتبه دهی مستندات و صفحاتی که نامشان حاوی عبارات جستجوی مورد درخواست است، استفاده شده اند.
URLها در نوار آدرس مرورگر وب ظاهر شده و در حالی که این امر تاثیر کمی بر موتورهای جستجو دارد، ساختار URL ضعیف و طراحی، می تواند منجر به تجربه منفی کاربر شود.
URL موجود در شکل بالا، به عنوان یک متن لینک anchor برای اشاره به صفحه ی مورد مراجعه در این پست بلاگ، مورد مراجعه واقع می شود.
خود را در ذهن کاربر قرار داده و به URL خود بنگرید. اگر شما می توانید به راحتی و درستی محتوایی را که می خواهید بر صفحه بیابید، پیش بینی کنید، URL شما به طور مناسب طراحی شده است. نیاز به بیان آخرین جزئیات در URL خود ندارید اما یک ایده ی ناهموار، یک نقطه شروع خوب است.
هر چه کوتاهتر باشد، بهتر است
در حالی که یک URL شرح دهنده، مهم است، حداقل سازی طول و به همراه اسلش بودن، کپی و چسباندن URL شما را راحتتر می سازد (در ایمیل ها، بلاگ ها، پیام های متنی و غیره) و در نتایج جستجو کاملا قابل مشاهده است.
اگر صفحه ی شما، یک عبارت یا اصطلاح خاص را مورد هدف قرار می دهد، اطمینان حاصل کنید که در URL شامل شود، اما از آن به شکل زیاده روی استفاده نکنید چون استفاده ی بیش از حد منجر به URL با قابلیت استفاده ی کمتر شده و در فیلترهای هرزنامه گیر خواهید افتاد.
ایستا بمانید
بهترین URLها، قابل خواندن توسط انسان و بدون پارامترها، اعداد و نمادهای زیاد هستند. با استفاده از تکنولوژی هایی نظیر mod-rewrite برای آپاچی و ISAPI-rewrite مایکروسافت، می توانید به راحتی URLهای پویا، نظیر www.seomoz.org/blog?id=123 را به نسخه ی ایستا با قابلیت خواندن بیشتر نظیر: http://www.seomoz.org/blog/google-fresh-factor
تبدیل کنید. حتی پارامترهای پویای واحد در یک URL می تواند منجر به رتبه بندی و اندیس گذاری کلی پایین تر شوند.
برای جداسازی کلمات از خط ربط استفاده کنید
همه برنامه های کاربردی وب، جداسازهای تفسیری را به درستی نظیر "_"، جمع "+" یا فاصله "%20" استفاده می کنند، بنابراین از کاراکتر "_" برای جداسازی کلمات در یک URL، نظیر فاکتور gooogle-fresh برای مثال URL بالا، استفاده می کنیم.
محتوای تکراری، مهمترین و آزاردهنده ترین مشکل است که یک وبسایت می تواند با آن روبرو شود. در طول چند سال اخیر، موتورهای جستجو، به دلیل محتواهای تکراری و رتبه بندی پایین تر، آزار دیده اند.
Canonicalization زمانی رخ می دهد که دو یا بیشتر نسخه های تکراری از صفحه ی وب در URLهای مختلف رخ دهد. این امر با توجه به سیستم های مدیریت محتوای جدید خیلی معمول است. برای مثال، شما یک نسخه ی معمول از یک صفحه را ارائه کرده و یک نسخه ی "بهینه شده برای پرینت" با محتوای یکسان را نیز فراهم می کنید. محتواهای تکراری حتی می توانند بر چندین وبسایت ظاهر شوند. برای موتورهای جستجو، این امر یک مشکل بزرگ را نشان می دهد-کدام نسخه از محتوا را باید به پژوهشگران نشان دهند؟ در دایره های SEO، این مشکل اغلب به عنوان محتوای تکراری ذکر می شود-بعد با جزئیات بیشتر در اینجا بیان می شود.
موتورهای جستجو در مورد نسخه های تکراری از یک قطعه از اطلاعات، حساسند. برای فراهم کردن بهترین تجربه ی جستجو، آنها به ندرت چندین نسخه تکراری از یک محتوا را ارائه می کنند و بنابراین باید از میان نسخه ها، موردی را که احتمال بیشتری دارد اصلی باشد، انتخاب کند. نتیجه نهایی این است که سایر نسخه های تکراری با رتبه کمتری قرار می گیرند.
Canonicalization تمرینی است که محتوای شما را به شیوه ای سازماندهی می کند که هر قطعه ی واحد فقط و فقط یک URL دارد. اگر چندین نسخه از محتوا بر یک وبسایت دارید (یا وبسایت های مختلف)، چنین سناریویی رخ می دهد. کدام الماس، اصلی است؟

وقتی چندین صفحه با پتانسیل رتبه دهی خوب در یک صفحه ی واحد قرار گرفته اند، نه تنها دیگر با هم رقابت نمی کنند بلکه یک ارتباط قوی تر و معروفیت نسبت به حالت تکی ایجاد می کنند. این امر به طور مثبت، بر توانایی آنهایی برای رتبه بندی خوب در موتورهای جستجو تاثیر می نهد.
یک گزینه ی متفاوت از موتورهای جستجو، "تگ URL canonical" نامیده می شود که راه دیگری برای کاهش نمونه های محتوای تکراری بر یک وب سایت واحد است. این امر همچنین می تواند در طول وبسایت های مختلف از یک URL بر یک حوزه تا یک URL مختلف بر یک حوزه ی مختلف، استفاده شود.
از تگ canonical در صفحه ای استفاده کنید که حاوی محتوای تکراری است. هدف تگ canonical، به master URL اشاره می کند که می خواهید آن را رتبه بندی کنید.
<link rel=”canonical” href=”http://www.seomoz.org/blog”/ >
این به موتورهای جستجو می گوید که صفحه ی مورد نظر، باید به عنونان یک کپی از www.seomoz.org/blog در نظر گرفته شود و همه ی لینک و متریک محتوایی که موتور جستجو فراهم می کند باید به آن URL بازگردد.
تگ canonical URL، به شیوه های زیادی مشابه تغییر مسیر 301 از نقطه نظر SEO است. ضرورتا، شما به موتور می گویید که چندین صفحه باید به عنوان یکی باید در نظر گرفته شوند، بدون هدایت واقعی بازدیدکنندگان به URL جدید-اغلب برای کارکنان توسعه دهنده ی شما را از اندوه زیادی نجات می دهد.
برای کسب اطلاعات بیشتر در مورد انواع مختلف محتوای تکراری، این پست انجام شده توسط دکتر پت را ملاحظه نمایید.
تاکنون رتبه دهی 5 ستاره ای را در نتیجه ی جستجو مشاهده کرده اید؟ موتورهای جستجو، اطلاعات را از snippetهای تعبیه شده در صفحات وب، دریافت می کنند. این snippetهای غی، نوعی از داده ی ساختار یافته هستند که به وبمسترها امکان علامت گذاری محتوا را به گونه ای که اطلاعات را برای موتورهای جستجو فراهم کند، می دهند.
در حالی که استفاده از snippetهای غنی و داده ی ساختار یافته، یک عنصر مورد نیاز از موتورهای جستجویی است که به خوبی طراحی شده اند، پذیرش در حال رشد آن بدین معناست که وبمسترهایی که از این مزیت استفاده کرده اند، ممکن است از یک مزیت در برخی شرایط لذت ببرند.

متاسفانه، وب پر از صدها هزار (اگر میلیون ها نباشند) وبسایت هایی است کسب و کار و مدل های ترافیکشان بستگی به گلچین محتوای سایر وبسایت ها و استفاده از آن ها در دامنه خودشان است (برخی اوقات به راه هایی که به شکل عجیبی تغییریافته اند) این عمل به دست آوردن محتوای شما و نشر مجدد آن، “scraping” نامیده می شود و scrapers درآمد خوبی از طریق نمایش تبلیغات و بالابردن رتبه خودشان برای محتوای ارائه شده، به دست می آورند (از روی طعنه، اغلب خود برنامه ی adsense گوگل نیز به همین گونه است).
وقتی شما محتوا را در هر نوعی از فرمت ارائه می کنید –RSS/XML و غیره- اطمینان حاصل کنید که آنرا از طریق سرویس های بلاگ/ردیابی عمده ارائه می کنید (نظیر technorati گوگل، یاهو و غیره). می توانید دستورالعمل های چگونگی کار با این سرویس ها نظیر گوگل و technorati را به طور مستقیم از سایتشان مشاهده نمایید یا از سرویسی نظیر pingomatic برای خودکار کردن فرآیند استفاده نمایید. اگر نرم افزار شما ساخت سفارشی باشد، معمولا برای توسعه دهندگان عاقلانه است که نشر خودکار را در آن بگنجانند.
بعد، می توانید از تنبلی scarpers استفاده کنید. بیشتر scrapersها بر وب، محتوا را بدون ویرایش نشر می دهند، بنابراین لینک هایی را گسترش می دهند که به وبسایت شما برمی گردد و می توانید مطمئن باشید که موتور جستجو بیشتر این لینک ها را به شما برمی گرداند (و نشان می دهد که منبع شما همان منبع اصلی است). برای انجام این کار، نیاز به استفاده از لینک های مطلق به جای لینک های داخلی در ساختار لینک بندی هستید. بنابراین به جای لینک به صفحه خانگی خود:
از شکل زیراستفاده کنید:
بدین شکل، وقتی که یک scraper محتوای شما را برداشته و کپی می کند، لینک به سایت شما اشاره می کند.
راه های خیلی پیشرفته تری برای محافظت در مقابل scraping وجود دارد، اما هیچ یک از آن ها ، کاملا محفوظ از شکست و خطا نیست. شما باید انتظار داشته باشید که هر چه سایت شما معروفتر می شود، بیشتر محتوای سایت شما scraped می شود و دوباره منتشر می شود. بسیاری از دفعات، می توانید از این مساله صرفنظر کنید، اما اگر خیلی جدی شوید و متوجه شوید که رتبه و ترافیک شما توسط scraperها گرفته شده است، می توانید از یک فرآیند قانونی که DMCA takedown نامیده می شود، استفاده کنید. خوشبختانه، کنسول درون خانه ی SEOmoz، راه حلی عالی برای حل این مشکل دارد-یافتن راه هایی برای حصول اطمینان از تقویت کپی رایتتان: چه کار کنید وقتی که محتوای آنلاین شما، دزدیده شده است.













ارسال نظر